
Un nuovo articolo di approfondimento di Eleonora Pantò per la rubrica Appunti Selvaggi
In copertina immagine creata con Imagen 3 di Gemini [*prompt 1]
Gli assistenti IA che utilizzano chatbot basati su modelli linguistici (LLM) sono ormai largamente diffusi e utilizzati per attività professionali, di studio e anche per la vita privata, come l’organizzazione di un viaggio. Si risparmia tempo, soprattutto quando abbiamo chiaro il compito che vogliamo svolgere e conosciamo bene il contesto in cui si applica: le attività più semplici e banali sono più facilmente automatizzabili, come rispondere a una mail, ma grazie alle funzionalità sempre nuove che sono offerte si possono creare veri e propri flussi di lavoro.
Per comprendere i concetti di base delle IA generative, in cui sono inclusi gli LLM, rimandiamo alla recente pubblicazione “La cultura è pronta all’impatto delle IA? 20 domande che dovremmo porci” [1], realizzata dal gruppo di lavoro Digital Cultural Heritage di ICOM Italia e disponibile gratuitamente. Il testo, pensato per le istituzioni culturali, i musei e le biblioteche, include la spiegazione di termini tecnici in modo chiaro e conciso e affronta il tema del copyright e della sostenibilità ambientale. Le risposte alle domande sono disponibili in italiano e in inglese.
Sulle attività che possono essere velocizzate o migliorate dagli assistenti in biblioteca, quali il supporto nell’attività di reference o nella catalogazione e metadatazione, sono disponibili online articoli e presentazioni [2] [3]. Un assistente può essere utile per rendere più accessibile la conoscenza, offrendo servizi di traduzione o adattamento di testi, semplificazioni del linguaggio, riassunti, rappresentazioni tramite mappe mentali o conversioni da testo a voce e viceversa. I bibliotecari possono essere una risorsa preziosa nel trasferire nuove competenze di “AI literacy”, quali la formulazione di prompt e la valutazione critica delle risposte: è sempre necessario ricontrollare e non affidarsi ciecamente a questi “oracoli”.
Vista la moltiplicazione di strumenti sempre più sofisticati, come fare a scegliere lo strumento più adatto alle proprie esigenze e magari integrarlo in base al compito da svolgere? Secondo una prima mappatura, realizzata dal corso del Politecnico di Milano “Imparare con l’IA”, [4] che consiglio caldamente, possiamo suddividere gli LLM in generalisti, integrati con altri sistemi già esistenti e specialistici.
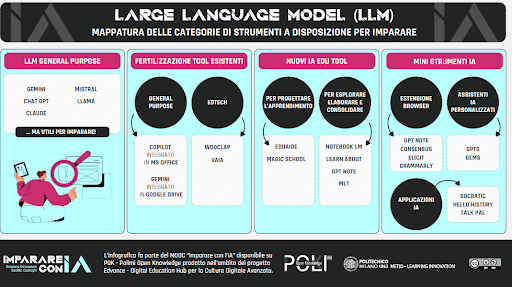
In questo primo articolo, descriveremo gli LLM generalisti quali Claude, DeepSeek, Gemini, mentre approfondiremo altri sistemi nelle prossime uscite di “Pillole di IA literacy”.
Anthropic Claude: la carta costituzionale dell’IA
Daniela e Dario Amodei, sono fratelli e fondatori di Anthropic, la società benefit che ha prodotto Claude: entrambi figure di spicco di OpenAI, la casa madre di ChatGPT, se ne sono andati quando è stato evidente che il progetto iniziale di creare un’IA aperta e al servizio dell’umanità non era più la missione distintiva.
Claude si caratterizza per un approccio innovativo per un’IA, chiamato “Constitutional AI” (CAI) [5]: si tratta della “costituzione” che definisce i principi e i valori che guidano il comportamento dell’IA, quali il rispetto dell’autonomia individuale, la minimizzazione del danno e il benessere collettivo. Il processo CAI è strutturato in diverse fasi, che prevedono dopo l’addestramento, un processo di autocritica interna, una revisione basata sul feedback umano e un’ulteriore revisione per il rispetto dei principi costituzionali. Questa caratteristica rende Claude un modello flessibile per gestire situazioni critiche e complesse.
Le diverse IA di Claude e le sue peculiarità
Come tutti i sistemi citati in quest’articolo, Claude è una famiglia di intelligenze diverse: Haiku, la più veloce e meno dettagliata, Sonnet una combinazione di efficienza e velocità e Opus con le prestazioni migliori adatta ad analisi approfondite e complesse, coding e matematica. Quando si fanno confronti su prestazioni e caratteristiche è sempre necessario indicare precisamente a quale IA si fa riferimento, perché i servizi a pagamento spesso hanno prestazioni molto migliori e offrono garanzie di riservatezza.
Dal 20 di marzo, Claude accede a Internet e quindi può offrire informazioni aggiornate.
La tokenizzazione
Una delle caratteristiche peculiari di Claude è che si presta molto bene all’analisi di testi lunghi. Vale la pena qui di fare un piccolo approfondimento sul concetto di token. Nella guida di ICOM citata in apertura, il token è descritto come “una sequenza di caratteri che costituisce un’unità minima dotata di significato di una lingua, e nella maggior parte dei casi coincide con una parola o una porzione di parola (più grande di una sillaba)”.

Nella figura vediamo come il tokenizer di OpenAI – GPT 4o e GPT 4oi dividono un testo (Il sentiero dei nidi di ragno) in token: ogni LLM utilizza diversi modi di suddivisione in token e solitamente è indicato sul proprio sito. Forse avrete letto storielle sugli errori grossolani delle IA nei calcoli, o sugli errori nel rispondere a “quante R ci sono nella parola Strawberry”: per farla breve gli LLM non hanno il concetto di “r=lettera dell’alfabeto” e quindi sono in difficoltà nell’elaborare una risposta corretta [6]. Ogni LLM elabora una quantità di token limitata per volta: Claude ha una capacità di elaborazione per un contesto fino a 200k token, superiore a ChatGPT e DeepSeek (ma inferiore a Gemini). La quantità di token elaborati è uno dei parametri dimensionali delle IA e alla base della definizione del prezzo [7].
I guardrail delle IA
Generalmente i sistemi di intelligenza generativa sono progettati per non fornire output pericolosi, come istruzioni per creare armi. Ma anche le IA possono essere hackerate, attraverso lo scardinamento dei sistemi di sicurezza – chiamati genericamente guardrail – con attività definite di jailbreaking che forzano le IA a superare i limiti imposti. Come abbiamo visto, Claude è progettato per adottare principi etici e per questo pone particolare attenzione alla sicurezza, attraverso iniziative specifiche per contrastare questo fenomeno, come sfide aperte con premi per chi supera le barriere protettive messe in atto.
Un caso di studio
Claude è particolarmente interessante per le sue caratteristiche di progettazione orientate all’affidabilità informativa e all’inclusività. Il sistema fornisce trasparenza sui limiti della propria conoscenza ed è addestrato per evitare bias discriminatori. La dimensione ampia della finestra di contesto lo rende adatto all’analisi di testi lunghi. Un caso studio interessante è quello del Parlamento Europeo ha implementato “Ask the EP Archives” (Archibot), un assistente AI basato su Claude, per rendere accessibili oltre 2,1 milioni di documenti ufficiali a ricercatori, responsabili politici, educatori e pubblico. Il progetto ha ridotto i tempi di ricerca e analisi dei documenti dell’80%, offrendo un accesso efficace alla storia europea [8].
![Immagine creata con Imagen 3 di Gemini [*prompt 2]](https://www.saperedigitale.org/wp-content/uploads/2025/04/imgine_gemini.png)
Immagine creata con Imagen 3 di Gemini [*prompt 2]
Gemini: l’integrazione con il mondo Google
Gemini (pronuncia Gemin-ai) racchiude tutte le IA offerte da Google e ha sostituito il predecessore “Bard”. Il nome si ispira alla costellazione dei Gemelli, in cui sono rappresentati Castore e Polluce: anche Gemini ha raggruppato i due team DeepMind e Google Research Brain .
Gli inventori del Transformer
Ai ricercatori di Google dobbiamo una delle innovazioni principali nell’utilizzo dei LLM, il modello Transformer del 2017 che “analizza i token (parole o porzioni di parole) all’interno di un testo e poi le relazioni fra i vari token, per determinare qual’è quello più importante. Quest’analisi si svolge in unico passaggio e non attraverso passi sequenziali come nelle reti neurali: ciò rende il sistema molto più efficiente, permettendogli di identificare il significato all’interno di uno specifico contesto e di produrre variazioni o sintesi plausibili”[9].
L’integrazione delle applicazioni Google
Uno dei punti di forza di Gemini è la sua integrazione con Google Search, superando in questo modo i limiti delle basi dati di aggiornamento che per forza di cose sono fermi a date precise. Nel caso la risposta citi una pagina web, Gemini fornisce il link alla pagina o anche la miniatura della pagina web. Gemini, il cui rilascio è recente (fine 2024) è stato addestrato in modo multimodale e può comprendere testo, audio, video, note scritte a mano, identificare oggetti dalle foto, comprendere foto con testi sfocati e generare immagini. A Gemini potete chiedere una ricetta facendo la foto degli ingredienti che avete a disposizione. Le immagini sono generate con Imagen 3 e non c’è un limite quotidiano.
Gemini è disponibile in 26 lingue diverse, anche se è prevalentemente addestrato su testi in inglese e l’assistente vocale è molto potente. Gemini comprende una famiglia di IA con caratteristiche diverse: da segnalare che Gemini utilizza le finestre di contesto più ampie di tutti il modello 1.5 Flash, usa 1 milione di token e il modello 1.5 Pro arriva a 2 milioni di token. Un milione di token equivalgono a 8 romanzi di lunghezza media o cinquanta mila righe di codice o 200 podcast.
AI overview Dire che ogni giorno questi servizi offrono nuove funzionalità non è un’esagerazione. Dalla fine di marzo è disponibile anche in Italia l’integrazione AI overview che risponde alle ricerche complesse con una sola domanda e con i link in evidenza per verificare le fonti.
DeepSeek: il gamechanger dell’IA
DeepSeek è stato rilasciato a dicembre 2024 da un’azienda cinese che ha pubblicato su GitHub (il principale repository di software open source) un documento in cui ha dichiarato che il proprio modello R1 aveva ottenuto risultati comparabili o migliori dei sistemi di IA già affermati come ChatGPT di OpenAI, LLama di Meta e Claude di Anthropic. L’aspetto importante è che tali prestazioni sono state ottenute con costi ridotti (si è parlato di 6 milioni contro i 600 di OpenAI) e utilizzando hardware non di fascia alta e con un notevole risparmio energetico. Queste ha provocato un terremoto in borsa: i giganti dell’IA hanno visto ridursi di un trilione di dollari le loro quotazioni e la Nvidia, produttrice dei chip utilizzati per le elaborazioni delle IA, ha perso 589 miliardi di dollari di valutazione nella più grande perdita di mercato in un giorno nella storia degli Stati Uniti. [10] In Cina i chip di fascia alta della Nvidia non sono accessibili, per cui i ricercatori hanno fatto di necessità virtù, introducendo un nuovo approccio che utilizza generalmente numeri meno precisi, e solo quando necessario aumenta la precisione; inoltre suddivide gli incarichi a una “mixture of experts” (MoE) cioè dividendo i modelli in sottomodelli utilizzati in modo dinamico in base alle necessità. Altre interpretazioni suggeriscono che DeepSeek abbia utilizzato i chip più potenti ma che non possa dichiararlo a causa delle limitazioni commerciali e che tutta l’operazione sia legata a manovre finanziarie per destabilizzare il mercato statunitense.
DeepSeeK utilizza un modello open source e può essere installato in locale dai singoli utenti. Questa caratteristica – che dovrebbe essere positiva in quanto garantirebbe maggiore trasparenza – sta sollevando le preoccupazioni di OpenAI che propone di vietare le IA open source (oltre a DeepSeek, ce ne sono molte altre come LLama, Mistral ecc.), in quanto più facilmente manipolabili per scopi malevoli, senza spiegare come ci si potrebbe tutelare da usi malevoli fatti da sistemi chiusi. Siamo senza dubbio di fronte a uno scontro commerciale e politico [11].
DeepSeek ha appena annunciato la versione V3, che secondo gli analisti ha prestazioni tre volte superiori al modello precedente.
Al momento l’uso di DeepSeek è totalmente gratuito, non accetta file in input e non è multimodale – cioè non gestisce audio e immagini, ma può analizzare il codice. Il dialogo non è raffinato come quello di altri sistemi: il tono è pragmatico ma efficace. La sua principale caratteristica è di essere stato addestrato su lingue asiatiche che al momento lo rendono abbastanza unico. La sua base dati di addestramento è statica e quindi non può dare risposte su argomenti di attualità. I punti di forza di DeepSeek sono la sua capacità di ragionamento matematico e logico, la capacità di scrittura e sintesi in cinese e la possibilità di crearsi dei modelli IA privati.
In sintesi
Stiamo vivendo in una fase di grande espansione dell’IA, annunci di miglioramenti della prestazioni e nuove funzionalità sono quotidiani e ogni volta l’effetto wow è quasi garantito. L’uso di diversi sistemi è legato al tipo di azioni che intendiamo svolgere: possiamo proporre lo stesso prompt ad assistenti diversi per capire quando sono accurate e fattuali le risposte, se abbiamo bisogno di scrivere dei testi possiamo vedere qual di questi sistemi ha uno stile che ci piace di più, se ci serve un’applicazione multimodale perché dobbiamo lavorare con le immagini o fare analisi di dati, quanto la privacy è rispettata – per questo conviene sempre acquistare un servizio a pagamento- e quanto si integra con i sistemi che già stiamo usando per esempio Google o Microsoft, ecc.
Nelle prossime uscite di Pillole di IA, approfondiremo altre applicazioni di assistenti IA .
[*prompt1 crea un’immagine fotorealistica di una biblioteca del futuro, ricca di ambienti diversi per imparare, usare videogiochi, ascoltare podcast includi persone di diversa età e una bibliotecaria non tradizionale che usa un assistente ai come gemini per il suo lavoro]
[*prompt2 crea un’illustrazione di una bibliotecaria in un biblioteca innovativa molto green e senza troppi libri sugli scaffali ma con diverse possibilita’ di apprendimento come stampanti 3d, visori xr, zone di lettura, ascolto podcast e rappresenta un assistente ai non come un robot ma come una collega che la supporta ad esempio nelle attivita’ di reference]
[1] Orlandi, S. D., De Angelis, D., Giardini, G., Manasse, C., Marras, A. M., Bolioli, A., & Rota, M. (2025). IA FAQ INTELLIGENZA ARTIFICIALE – AI FAQ ARTIFICIAL INTELLIGENCE. Zenodo. https://doi.org/10.5281/zenodo.15069460 in italiano e inglese
[3] https://medium.com/@andy.bosyi/document-classification-and-tagging-with-llm-and-ml-ea404599dcc6
[4] https://www.pok.polimi.it/course/view.php?id=175#tab2
[6] https://iapertutti.it/token-intelligenza-artificiale-come-funziona/
[7] https://ikala.ai/blog/ai-trends/deepseek-llm-comparison_en/
[8] https://www.01net.it/il-parlamento-europeo-amplia-laccesso-ai-propri-archivi-con-claude-ai/
[9] https://laricerca.loescher.it/in-principio-era-il-bot/
Eleonora Pantò – 26 marzo 2025